在今天的文章里我想演示下SQL Server里在表上丢失索引如何引起死锁(deadlock)的。为了准备测试场景,下列代码会创建2个表,然后2个表都插入4条记录。
1 -- Create a table without any indexes 2 CREATE TABLE Table1 3 ( 4 Column1 INT, 5 Column2 INT 6 ) 7 GO 8 9 -- Insert a few record10 INSERT INTO Table1 VALUES (1, 1)11 INSERT INTO Table1 VALUES (2, 2)12 INSERT INTO Table1 VALUES (3, 3)13 INSERT INTO Table1 VALUES (4, 4)14 GO15 16 -- Create a table without any indexes17 CREATE TABLE Table218 (19 Column1 INT,20 Column2 INT21 )22 GO23 24 -- Insert a few record25 INSERT INTO Table2 VALUES (1, 1)26 INSERT INTO Table2 VALUES (2, 2)27 INSERT INTO Table2 VALUES (3, 3)28 INSERT INTO Table2 VALUES (4, 4)29 GO
在我向你重现死锁前,先看下列的代码,它是个简单的UPDATE语句,在第1个表里更新一个指定行。
1 -- Acquires an Exclusive Lock on the row2 UPDATE Table1 SET Column1 = 3 WHERE Column2 = 1
因为在Column2上没有索引定义,对于我们的UPDATE语句,查询优化器在执行计划里必须选择表扫描(Table Scan)运算符来查找符合的记录:

这就是说我们必须扫描整个堆表来找我们想更新的行。在那个情况下,SQL Server用排它锁(Exclusive Lock)锁定表里的第1行。当你在不同的会话执行一个SELECT语句,引用另一个堆表里“将发生”的行,表扫描(Table Scan)运算符会阻塞,因为首先你必须读取所有堆表里“已发生”的行,即获取你查询里逻辑请求的行。
-- This query now requests a Shared Lock, but get's blocked, because the other session/transaction has an Exclusive Lock on one row, that is currently updatedSELECT Column1 FROM Table1WHERE Column2 = 4
表扫描(Table Scan)默认意味这你必须扫描整个表,因此你必须在每条记录上获得共享锁(Shared Lock)——即使在你逻辑上不请求的记录上。如果你用不同的顺序,在不同的会话里访问2个表,当你从同个表尝试读写时,这个情况会导致死锁情形。下面代码显示来自第1个查询的事务:
1 BEGIN TRANSACTION 2 3 -- Acquires an Exclusive Lock on the row 4 UPDATE Table1 SET Column1 = 3 WHERE Column2 = 1 5 6 -- Execute the query from Session 2... 7 -- This query acquires an Exclusive Lock on one row from Table2... 8 9 -- This query now requests a Shared Lock, but get's blocked, because the other session/transaction has an Exclusive Lock on one row, that is currently updated10 SELECT Column1 FROM Table211 WHERE Column2 = 312 13 ROLLBACK TRANSACTION14 GO
下面显示来自第2个事务的代码:
1 BEGIN TRANSACTION 2 3 -- Acquires an Exclusive Lock on the row 4 UPDATE Table2 SET Column1 = 5 WHERE Column2 = 2 5 6 -- Continue with the query from Session 2... 7 -- This query now requests a Shared Lock, but get's blocked, because the other session/transaction has an Exclusive Lock on one row, that is currently updated 8 9 -- This query now requests a Shared Lock, but get's blocked, because the other session/transaction has an Exclusive Lock on one row, that is currently updated10 SELECT Column1 FROM Table111 WHERE Column2 = 412 13 ROLLBACK TRANSACTION14 GO
从2个事务可以看到,2个表在不同的顺序里被访问。如果时机合适,在同个时间运行这2个事务会导致死锁(deadlock)情形。假设下列的执行顺序:
- 在Table1上第1个事务运行UPDATE语句。
- 在Table2上第2个事务运行UPDATE语句。
- 在Table2上第1个事务运行SELECT语句。这个SELECT语句会阻塞,因为表扫描(Table Scan)运算符想要在行上获得的共享锁(Shared Lock),已经被第2个事务排它锁(exclusively lock)锁定。
- 在Table1上第2个事务运行SELECT语句。这个SELECT语句会阻塞,因为表扫描(Table Scan)运算符想要在行上获得的共享锁(Shared Lock),已经被第1个事务排它锁(exclusively lock)锁定。
下图演示了这个死锁情形:
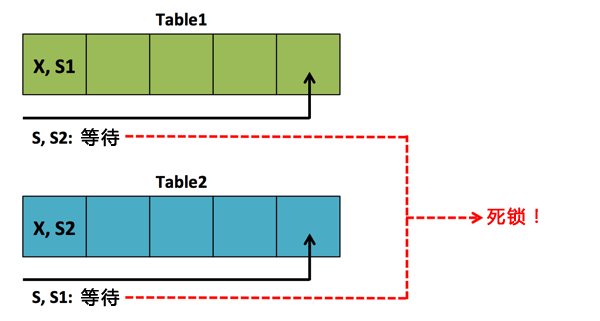
现在2个事务相互阻塞,因此在SQL Server里你引起了死锁。在那个情况下死锁监控器(Deadlock Monitor)后台进程踢入,进行最“便宜”的事务的回滚(基于事务需要写入事务日志的字节数)。
你可以在2个表里通过为Column2提供一个索引来轻松解决这个死锁。在那个情况下SQL Server可以进行符合列的查找(Seek)运算符操作,因此当你执行SELECT语句时,可以跳过已经在索引叶子层的锁定行:
1 CREATE NONCLUSTERED INDEX idx_Column2 ON Table1(Column2)2 CREATE NONCLUSTERED INDEX idx_Column2 ON Table2(Column2)3 GO
下图演示了现在的死锁情形是怎样的:

使用查找操作你可以跳过索引叶子层的锁定行,你可以避免我们已经讨论过的死锁。因此当你在你的数据库看到死锁情形时,仔细看下你的索引战略(设计),这非常重要!在SQL Server里,索引一直是一个很重要的东西——始终记住这个!
感谢关注!